UPGMA
UPGMA (unweighted pair group method with arithmetic mean; česky metoda neváženého párování s aritmetickým průměrem) je jednoduchá aglomerativní hierarchická shluková metoda (jde o tzv. bottom-up metodu, kdy se nejprve shlukují páry sobě nejpodobnější, které se následně shlukují až do konečné sítě). Metodu představili Sokal a Michener.[1]
Termín nevážená metoda nesouvisí s matematickým výpočtem, ale odkazuje na skutečnost, že všechny distance se podílejí stejnou měrou na výpočtu každého průměru. Metoda UPGMA má i alternativu váženého párování, která se nazývá WPGMA. WPGMA generuje výsledky na základně jednoduchého průměru vzdáleností (neboli distancí), zatímco u nevážené metody UPGMA se používá k výpočtu proporcionální průměr (viz pracovní příklad).[2]
Algoritmus
Algoritmus UPGMA vytváří zakořeněný strom (tzv. dendrogram), který odráží strukturu matice podobností (nebo matice odlišností). V každém kroku jsou dva nejpodobnější klastry sloučeny do klastru vyšší úrovně. Vzdálenost mezi každými dvěma klastry a o velikosti (neboli mohutnosti) a je vypočítána jako průměr všech vzdáleností mezi páry prvků v a v , tzn. jako střední vzdálenost mezi prvky každého klastru:








Jinými slovy, v každém kroku se aktualizuje vzdálenost mezi nově spojenými klastry a novým clustrem . Aktualizovaná vzdálenost je dána proporcionálním průměrem vzdáleností a :





Algoritmus UPGMA vytváří zakořeněné dendrogramy, při jejichž tvorbě předpokládá konstantní podíly - to znamená, že předpokládá tzv. ultrametrický strom, ve kterém jsou vzdálenosti od kořene ke konci každé větve stejné. Pokud jsou základem pro tvorbu stromu molekulární data (tj. DNA, RNA nebo proteiny) odebraná ve stejný čas, ultrametricita se stane ekvivalentem molekulárních hodin.
Pracovní příklad
Tento pracovní příklad je založen na matici genetických distancí JC69, která je odvozená z alignmentu sekvencí 5S ribozomální RNA pěti bakterií: Bacillus subtilis (), Bacillus stearothermophilus (), Lactobacillus viridescens (), Acholeplasma modicum () a Micrococcus luteus ().[3][4]





První krok
- První shlukování (klastrování)
Předpokládejme, že máme pět prvků uspořádaných v následující matici párových vzdáleností :


| a | b | c | d | e | |
|---|---|---|---|---|---|
| a | 0 | 17 | 21 | 31 | 23 |
| b | 17 | 0 | 30 | 34 | 21 |
| c | 21 | 30 | 0 | 28 | 39 |
| d | 31 | 34 | 28 | 0 | 43 |
| e | 23 | 21 | 39 | 43 | 0 |
Protože je v této matici je nejmenší hodnotou , v prvním kroku spojíme prvky a .

- Odhad délky první větve
Písmenem označme uzel, ve kterém se nyní spojují prvky a . Díky rovnici je zajištěno, že prvky a jsou stejně vzdálené od . To odpovídá hypotéze ultrametricity. Větve obou prvků a vedoucí k uzlu tedy mají délku (viz výsledný dendrogram).



- První aktualizace matice vzdáleností
Poté přistoupíme k aktualizaci počáteční matice na novou matici (viz níže), která bude zmenšená o jeden řádek a jeden sloupec kvůli seskupování s v předchozím kroku. Nové hodnoty vzdáleností odpovídají průměru vzdáleností mezi každým prvkem prvního klastru a každým ze zbývajících prvků:





Nově vypočtené hodnoty vzdáleností v matici jsou vyznačeny tučně. Hodnoty psané kurzívou v matici nebyly změněny oproti původní matici , protože jde o vzdálenosti mezi prvky, které nebyly zahrnuty do prvního klastru.
Druhý krok
- Druhé shlukování
Nyní zopakujeme tři předchozí kroky, počínaje tvorbou nové matice vzdálenosti
| (a, b) | c | d | e | |
|---|---|---|---|---|
| (a, b) | 0 | 25.5 | 32.5 | 22 |
| c | 25.5 | 0 | 28 | 39 |
| d | 32.5 | 28 | 0 | 43 |
| e | 22 | 39 | 43 | 0 |
V této matici je nejmenší hodnotou , proto ke klastru připojíme prvek .

- Odhad délky druhé větve
Označme uzel spojující klastr a prvek písmenem . Kvůli ultrametricitě musí mít větve spojující klastr (, ) a v uzlu stejnou délku:


Délku nové větve vypočteme následovně: (viz výsledný dendrogram)

- Druhá aktualizace matice vzdáleností
Poté přistoupíme k aktualizaci matice na novou distanční matici (viz níže), zmenšenou o jeden řádek a jeden sloupec kvůli vzniku nového klastru a . Tučně zvýrazněné hodnoty v odpovídají novým vzdálenostem, vypočteným na základně proporcionálního průměru:


Výpočet nové vzdálenosti pomocí proporcionálního průměru umožňuje vzít v potaz větší velikost klastru - dva prvky) s ohledem na (jeden prvek). Podobně vypočteme zbývající vzdálenost:


Proporcionální průměr tedy dává stejnou váhu všem počátečním vzdálenostem matice . To je důvod, proč je metoda nevážená - ne s ohledem na matematický postup, ale s ohledem na počáteční vzdálenosti.
Třetí krok
- Třetí shlukování
Znovu zopakujeme tři předchozí kroky, přičemž nejprve vytvoříme novou matici vzdáleností .
| ((a, b), e) | c | d | |
|---|---|---|---|
| ((a, b), e) | 0 | 30 | 36 |
| c | 30 | 0 | 28 |
| d | 36 | 28 | 0 |
Nejmenší hodnotou této matice je , takže spojíme prvky a .

- Odhad délky třetí větve
Písmenem označme uzel, který spojuje prvky a . Větve spojující a v uzlu pak mají délku (viz výsledný dendrogram)


- Třetí aktualizace matice vzdáleností
Nyní je třeba aktualizovat jen jednu hodnotu, přičemž je třeba mít na paměti, že každý z prvků a přispívají k výpočtu průměru hodnotou :


Poslední krok
Finální matice je následující:

| ((a, b), e) | (c,d) | |
|---|---|---|
| ((a, b), e) | 0 | 33 |
| (c,d) | 33 | 0 |
Spojili jsme tudíž oba klastry a .


Písmenem označme (kořenový) uzel, ve kterém spojíme klastry a . Větve klastrů a vedoucí k uzlu pak mají délky:


Vypočteme délky dvou zbývajících větví:


Výsledný dendrogram UPGMA
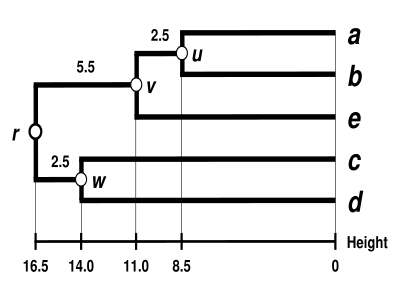
Dendrogram je nyní dokončen.[5] Je ultrametrický, protože všechny konce větví (od po ) jsou stejně vzdálené od uzlu :

Dendrogram je proto zakořeněn nejhlubším uzlem , který je nazýván kořen.
Porovnání s jinými algoritmy
Alternativní klastrovací schémata zahrnují single linkage clustering (metoda nejbližšího souseda, jednospojná metoda), complete linkage clustering (metoda nejvzdálenějšího souseda, všespojná metoda) a WPGMA. Jednotlivé algoritmy se mezi sebou liší použitím jiných postupů při výpočtu vzdáleností mezi klastry v rámci tvorby nové matice. Nevýhodou nejjednodušší metody single linkage clustering je tzv. chaining phenomenon, při kterém dochází ke shlukování klastrů na základě jediného společného charakteru přestože jsou si jednotlivé prvky v klastru obecně nepodobné. Algoritmus Complete linkage clustering dokáže tuto nevýhodu řešit a tvoří klastry o přibližně stejných diametrech.[6]
 |

|
 |
 |
| Single-linkage clustering | Complete-linkage clustering | Average linkage clustering: WPGMA | Average linkage clustering: UPGMA |
Použití
- Jde o jednu z nejpopulárnějších metod v ekologii. Požívá se pro klasifikaci vzorků (jako jsou např. vegetační snímky) na základě párových podobností jejich vlastností (jako je např. druhové složení).[7] Mimo vegetační data může sloužit také například k pochopení trofické interakce mezi mořskými bakteriemi a protisty.[7]
- V bioinformatice se UPGMA používá k tvorbě fenetických stromů (fenogramů). Metoda UPGMA byla původně navržena pro studie založené na proteinové elektroforéze, ale v současné době se nejčastěji používá k výpočtu vodících stromů pro sofistikovanější algoritmy. Tento algoritmus se používá například při výpočtu alignmentu sekvencí, kdy se na jeho základě tvoří pořadí, ve kterém budou sekvence alignovány. Vodící strom založený na UPGMA seskupuje nejpodobnějších sekvencí bez ohledu na jejich evoluční vývoj nebo fylogenetickou afinitu.[8]
- Při použití metody UPGMA ve fylogenetice se předpokládá konstantní rychlost evoluce (tzv. hypotéza molekulárních hodin) a že všechny vzorky byly odebrány současně. Nicméně se nepovažuje za vhodnou metodu pro odvozování fylogenetických vztahů. Metodu lze použít pouze pokud byly zmíněné předpoklady testovány a dobře zdůvodněny. Je důležité si uvědomit, že strom vytvořený na základě vzorků odebraných v různých časech by neměl vést k ultrametrickému stromu, dokonce i za podmínky „strict clock“.
Časová složitost
Základní použití UPGMA algoritmu ke konstrukci stromu má časovou komplexitu . Pokud použijeme pro každý klastr haldu, abychom jednotlivé klastry udželi ve vzdálenosti od ostatních, redukujeme čas na . Fionn Murtagh představil nějaké další přístupy pro speciální případy: časový algoritmus podle Day a Edelsbrunner[9] pro k-dimensionální data, kde je optimální pro konstantní k, a další algoritmus pro omezené vstupy, pokud „shlukovací strategie vyhovuje reducibilitě“.[10]




Odkazy
Reference
V tomto článku byl použit překlad textu z článku UPGMA na anglické Wikipedii.
- ↑ Sokal, Michener. A statistical method for evaluating systematic relationships. University of Kansas Science Bulletin. 1958, s. 1409–1438. Dostupné online. (anglicky)
- ↑ GARCIA S., PUIGBÒ P. "DendroUPGMA: A dendrogram construction utility" [online]. Dostupné online.
- ↑ Erdmann VA, Wolters J. Collection of published 5S, 5.8S and 4.5S ribosomal RNA sequences. Nucleic Acids Research. 1986, s. r1–59. DOI 10.1093/nar/14.suppl.r1. PMID 2422630. (anglicky)
- ↑ Olsen GJ. Phylogenetic analysis using ribosomal RNA. Methods in Enzymology. 1988, s. 793–812. DOI 10.1016/s0076-6879(88)64084-5. PMID 3241556. (anglicky)
- ↑ SWOFFORD DL, OLSEN GJ, WADDELL PJ, HILLIS DM. "Phylogenetic inference". In Hillis DM, Moritz C, Mable BK (eds.). Molecular Systematics. 2. vyd. Sunderland, MA: Sinauer, 1996. Dostupné online. ISBN 9780878932825. S. 407–514.
- ↑ EVERITT, B. S.; LANDAU, S.; LEESE, M. Cluster Analysis. 4. vyd. London: Arnold, 2001. S. 62–64.
- ↑ a b Vázquez-Domínguez E, Casamayor EO, Català P, Lebaron P. Different marine heterotrophic nanoflagellates affect differentially the composition of enriched bacterial communities. Microbial Ecology. April 2005, s. 474–85. DOI 10.1007/s00248-004-0035-5. PMID 16003474. JSTOR 25153200. (anglicky)
- ↑ Wheeler TJ, Kececioglu JD. Multiple alignment by aligning alignments. Bioinformatics. July 2007, s. i559–68. DOI 10.1093/bioinformatics/btm226. PMID 17646343. (anglicky)
- ↑ DAY, William H. E.; EDELSBRUNNER, Herbert. Efficient algorithms for agglomerative hierarchical clustering methods. Journal of Classification. 1984-12-01, s. 7–24. ISSN 0176-4268. DOI 10.1007/BF01890115. (anglicky)
- ↑ Murtagh F. Complexities of Hierarchic Clustering Algorithms: the state of the art. Computational Statistics Quarterly. 1984, s. 101–113. (anglicky)
Související články
Externí odkazy
- Implementace klastrovacího algoritmu UPGMA v Ruby (AI4R)
- Příklad výpočtu UPGMA pomocí matice podobnosti
- Příklad výpočtu UPGMA pomocí distanční matice
